
TeachLM: insights from a new LLM fine-tuned for teaching & learning
Six key takeaways, including what the research tells us about how well AI performs as an instructional designer

Hey folks 👋
As I and many others have pointed out in recent months, LLMs are great assistants but very ineffective teachers. Despite the rise of “educational LLMs” with specialised modes (e.g. Anthropic’s Learning Mode, OpenAI’s Study Mode, Google’s Guided Learning) AI typically eliminates the productive struggle, open exploration and natural dialogue that are fundamental to learning.
This week, Polygence, in collaboration with Stanford University researcher Prof Dora Demszky. published a first-of-its-kind research on a new model — TeachLM — built to address this gap.
In this week’s blog post, I deep dive what the research found and share the six key findings — including reflections on how well TeachLM performs on instructional design.
Let’s dive in! 🚀
The Research
The research started by identifying critical issues with current LLMs in educational contexts. The TLDR is that LLMs are optimised as “helpful assistants” that minimise cognitive friction, which directly contradicts effective pedagogical practices that require introducing productive struggle and withholding immediate answers.

Studies cited include a University of Pennsylvania finding that unfettered GPT-4 access for math tutoring can harm educational outcomes, and MIT research showing reduced brain connectivity in students using LLMs (Bastani et al, 2025).
The TeachLM team asked, what if instead of relying on prompt engineering or synthetic data, we fine tune an LLM with 100,000 hours of real student-tutor interactions? Their aim was to create a more effective AI tutor by training it on real interactions between learners and tutors.
In order to test their hypothesis, the team established six key metrics for evaluating AI’s educational performance:
Student talk time: Percentage of dialogue spoken by students (humans achieve ~30%, LLMs only 5-15%)
Average words per tutor turn: Human tutors average 72 words vs LLMs at 150-300 words
Questions per interrogative turn: Humans ask 1-2 questions vs LLMs asking 3-4
Dialogue duration: Human sessions average 150-160 turns vs LLMs ending at 30-80 turns
Context discovery: Ability to uncover student background and learning goals
Coding skills assessment: Whether models check technical prerequisites
Key Findings
1. Generic AI Models Consistently Underperform as Tutors Compared to Human Tutors
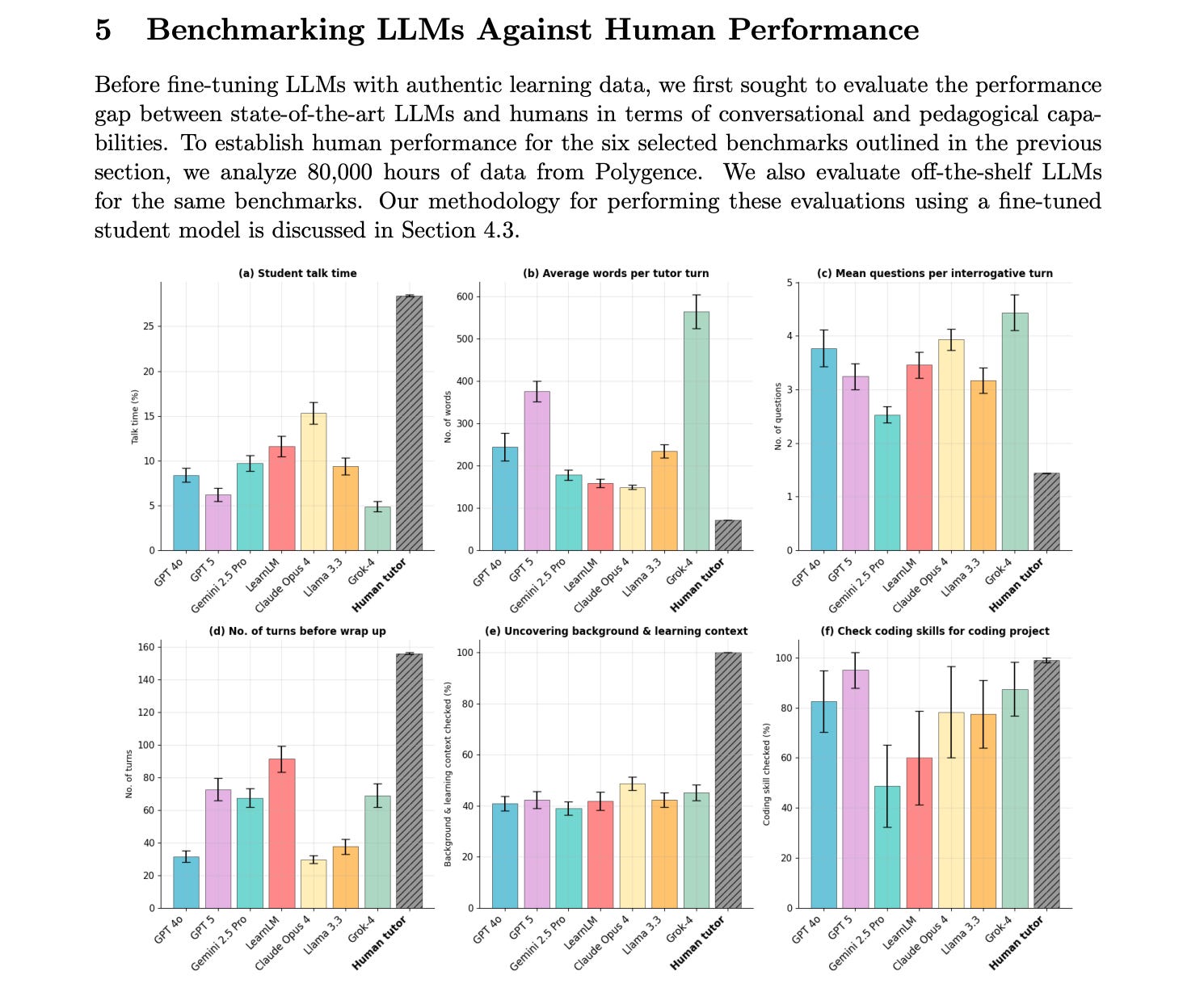
The paper compared human tutors with state-of-the-art LLMs across six pedagogical metrics. The researchers tested models from OpenAI, Google, Anthropic, Meta, and XAI, finding that off-the-shelf models consistently underperform compared to human tutors across all benchmarks.
2. Educational LLMs Also Consistently Underperform as Tutors
Another important finding was that current educational LLMs (Anthropic’s Learning Mode, OpenAI’s Study Mode, Google’s Guided Learning) show only marginal improvements over base models. Researchers manually tested three educational LLMs through dozens of multi-turn conversations across various learning scenarios, documenting specific behavioural patterns including:
Missing learning context: All three models spend minimal time establishing student background or learning goals
Multiple-choice-style questioning: Default to restrictive 3-option questions rather than open-ended inquiries
Wall of text responses: Verbose outputs that worsen as conversations progress
Inability to deal with confusion: Defaulting to rephrasing rather than diagnosing underlying issues
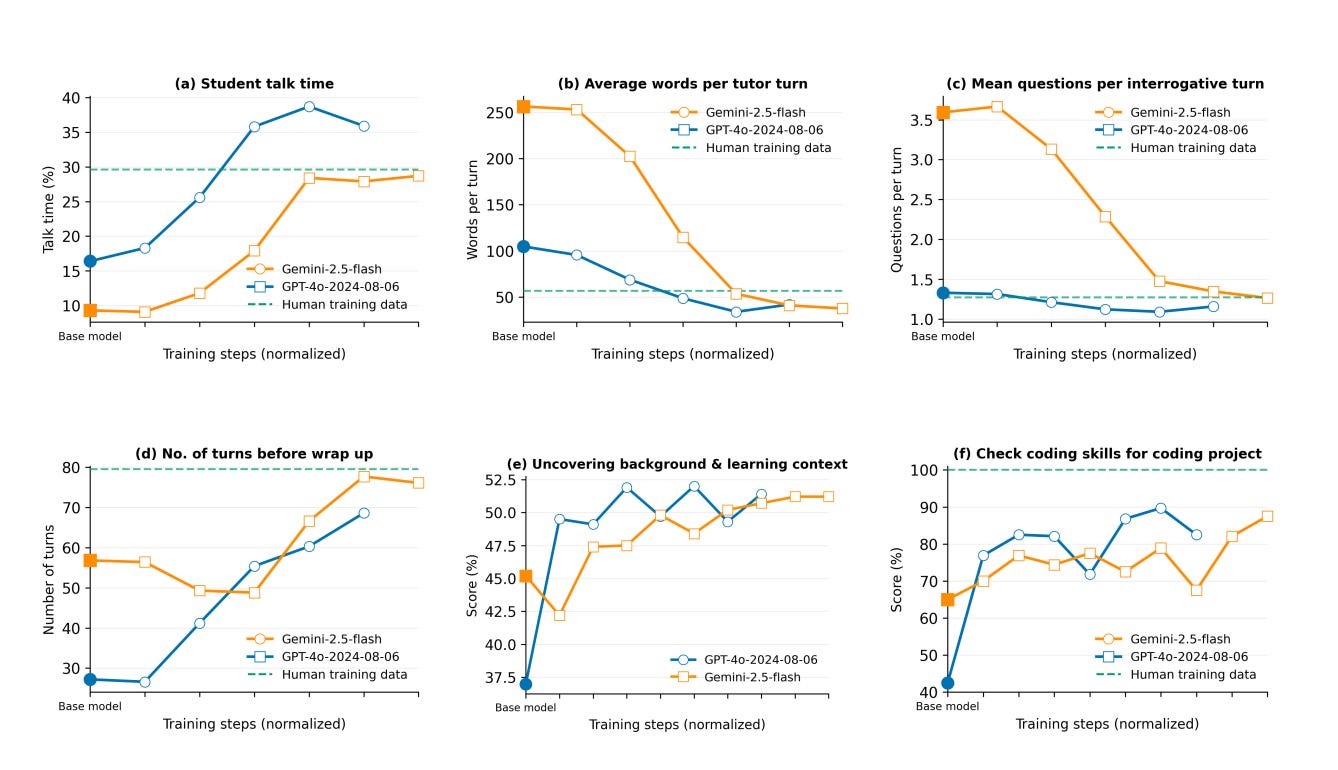
3. TeachLM Outperformed All Models on the Defined Criteria
Parameter-efficient fine-tuning on authentic learning data produced by human tutors and learners, led to substantial improvements in AI’s performance as an educator. Specifically, when compared with generic LLMs, TeachLM:
Doubled student talk time
Led to a 50% increase in dialogue turns
Improved questioning style with more natural, open-ended inquiries
Enhanced personalisation through better context discovery
Reduced verbosity with more appropriate turn lengths
4. New Insights on How to Build Effective Educational AI
During the study, the researchers discovered they needed different amounts of training time for different capabilities. Simple behaviours like “talk less” could be learned in a few training sessions, but complex skills like “diagnose why this specific student is confused about fractions” required more extensive training with a larger number of real student-teacher interactions.
This shows that despite the tendency to try to build “golden bullet” models or settings, we can’t expect LLMs’ pedagogical skills to improve at the same rate from one-sized fits all trining methods. Just as we do with human educators, we need to adapt AI’s training depending on the complexity and nuance of the task in question.
5. Humans Still Outperform LLMs on All Defined Metrics
Overall, all AI models - including TeachLM - underperform compared to human tutors across all metrics. The improvements represent progress toward human-level performance, but don’t surpass it:
1. Student Talk Time: Humans achieve ~30%, while off-the-shelf LLMs only allow 5-15% student talk time. TeachLM improves this but still falls short of human performance.
2. Average Words per Tutor Turn: Human tutors average only 72 words per turn, while most off-the-shelf models average 150-300 words. Fine-tuning reduces this but doesn’t reach human levels.
3. Questions per Interrogative Turn: Humans ask 1-2 questions per turn (average 1.5), while LLMs ask 3-4 questions. TeachLM settles in the 1-2 range but doesn’t surpass humans.
4. Dialogue Duration: Human sessions average 150-160 turns, while most LLMs end conversations at 30-80 turns. TeachLM increases dialogue length but remains below human performance.
5. Context Discovery: Most off-the-shelf models score 40-45% at uncovering student background, while TeachLM shows improvement but “absolute values are still far from 100%”.
6. Coding Skills Assessment: Human tutors check coding background “virtually any time the project involves coding,” while off-the-shelf models perform in the 50-80% range.
6. Humans Still Outperform LLMs on Instructional Design
Overall, all AI models — including TeachLM — underperform compared to humans on instructional design. While TeachLM shows measurable gains, it still lags behind human tutors in the core design behaviours that shape high-quality learning experiences:
Learner Analysis: Instructional Designers consistently elicit rich information about students’ goals, prior knowledge, motivation, and constraints. Off-the-shelf models recover only ~40–45% of that context; TeachLM improves this, but still falls well short of human-level coverage.
Prerequisite Checks: Instructional Designers check for required skills — such as coding — nearly 100% of the time when relevant. LLMs often skip these; TeachLM raises the rate but doesn’t consistently reach the human benchmark.
Pacing & Scaffolding: Instructional Designers structure sessions to support productive struggle over 150+ turns, pacing instruction based on student progress. Most LLMs — including TeachLM — still default to shorter, more abrupt sessions, often failing to sequence instruction adaptively.
Question Design: Instructional Designers typically ask 1–2 open-ended questions per turn to drive inquiry and reflection. While TeachLM adopts this format more reliably than other models, it doesn’t consistently match or optimise the strategic intent behind human questioning (e.g., diagnostic, metacognitive prompts).
In short, TeachLM behaves more instructional designer-like than generic AI models, especially in context gathering, questioning, and pacing. However, expert human Instructional Designers still outperform AI across established methods of Instructional Design.
Conclusion
TeachLM is a meaningful step towards AI that designs before it delivers—but the headline remains clear: great learning still starts with great human instructional design and optimal delivery happens when human tutors are front and centre.
Perhaps TeachLM’s biggest achievement is in the lessons it provides on how to build and train AI better in the education context:
Stop prompt-tweaking and train on authentic, longitudinal educational outputs, e.g. tutor-student dialogues.
Make pedagogical behaviours - not the speed of solutions or outputs - the objective.
Happy innovating!
Phil 👋
PS: Want to explore how AI is reshaping how we analyse, design, deliver & evaluate learning? Apply for a place on my AI & Learning Design Bootcamp where we dig into these concepts and get hands-on to develop key, future-ready skills.