
FRAME™: A Practical Method for Integrating AI into L&D Workflows
Aka, a 5-step process to maximise AI's value while actively managing its risks

Hey folks!
If you work in L&D, you’re more likely than not to already be using AI in your day to day work. The data is clear: in 2025, over 50% of L&D teams now consider AI (primarily, generic AI assistants like Copilot and ChatGPT) to be an established part of their toolkit, with usage expanding month on month across different phases of ADDIE—from analysis to evaluation (Taylor & Vinauskaitė, 2025).
For a profession held back for decades by slow, complex workflows, this should be good news: AI promises faster development, deeper personalisation and improved scalability.
But multiple studies also show that the majority of knowledge workers using AI are doing so in ways which are not just suboptimal but actively risky to performance and quality—with documented performance drops of up to 23% in some tasks.

In a field study with consultants from Boston Consulting Group (BCG), for example, researchers found that knowledge workers using AI without structured methods demonstrated what we might call “mis-calibrated trust” (BCG, 2023). The results were striking:
Over-trusted AI on tasks outside its strengths, leading to a drop in performance
Under-trusted AI where it actually excelled, missing real productivity gains
Couldn’t identify where AI was reliable versus where it was guessing
Researchers call this the “jagged frontier” of AI capability. The problem I’ve identified on the ground when working with L&D teams is that most of us don’t know where that frontier is, or how to manage it in order to optimise the upside of AI while actively mitigating the risks.
For us L&D professionals, the stakes are dangerously high. When we mis-calibrate our trust in AI, we don’t just lose productivity—we lose credibility and learner outcomes.
How do we build AI-augmented workflows for L&D that capture AI’s upside while actively managing the risks?
So, the question I asked is: how do we actually use AI reliably in L&D work? More specifically: how do modern LLMs work, what are their real strengths and weaknesses, and how do we build AI-augmented workflows for L&D that capture AI’s upside while actively managing the risks?
How LLMs Work (And Why it Matters)
The AI tools that L&D are using are general-assistance Large Language Models (LLMs) -- tools like ChatGPT, Copilot, Gemini and Claude (Taylor & Vinauskaitė, 2025).
When we work with these tools, we are working with pattern and prediction machines. LLMs generate responses by predicting what is most statistically likely to come next rather than what is optimal. Put another way, AI doesn’t actually “know” or “understand” anything--it predicts based on patterns.
The quality of AI’s predictions depends ultimately on the data it’s been trained on -- i.e. the resources it’s been fed by those who built it. Most general-purpose models (ChatGPT, Claude, Gemini, and Copilot) are pre-trained on a very large mix of content types, with varied quality and reliability. This includes:
Public web crawls (e.g., copies of blogs, forums, documentation sites, Wikipedia).
Licensed texts (books, news, reference works) via partnerships with publishers.
Open-source code repositories.
Curated datasets and academic text.
Synthetic/instruction data and reinforcement learning from human feedback (RLHF).
When we work with AI on Instructional Design tasks, outputs are shaped by a similarly large range of materials with varied levels of reliability. I did some research here and found that the Instructional Design knowledge of AI models is based on a very broad range of sources of very varied quality.

The result? AI’s instructional design “expertise” is essentially a statistical blend of everything ever written about learning—expert and amateur, evidence-based and anecdotal, current and outdated. Without a structured approach, you’re gambling on which patterns the model draws from, with no guarantee of pedagogical validity or factual accuracy.
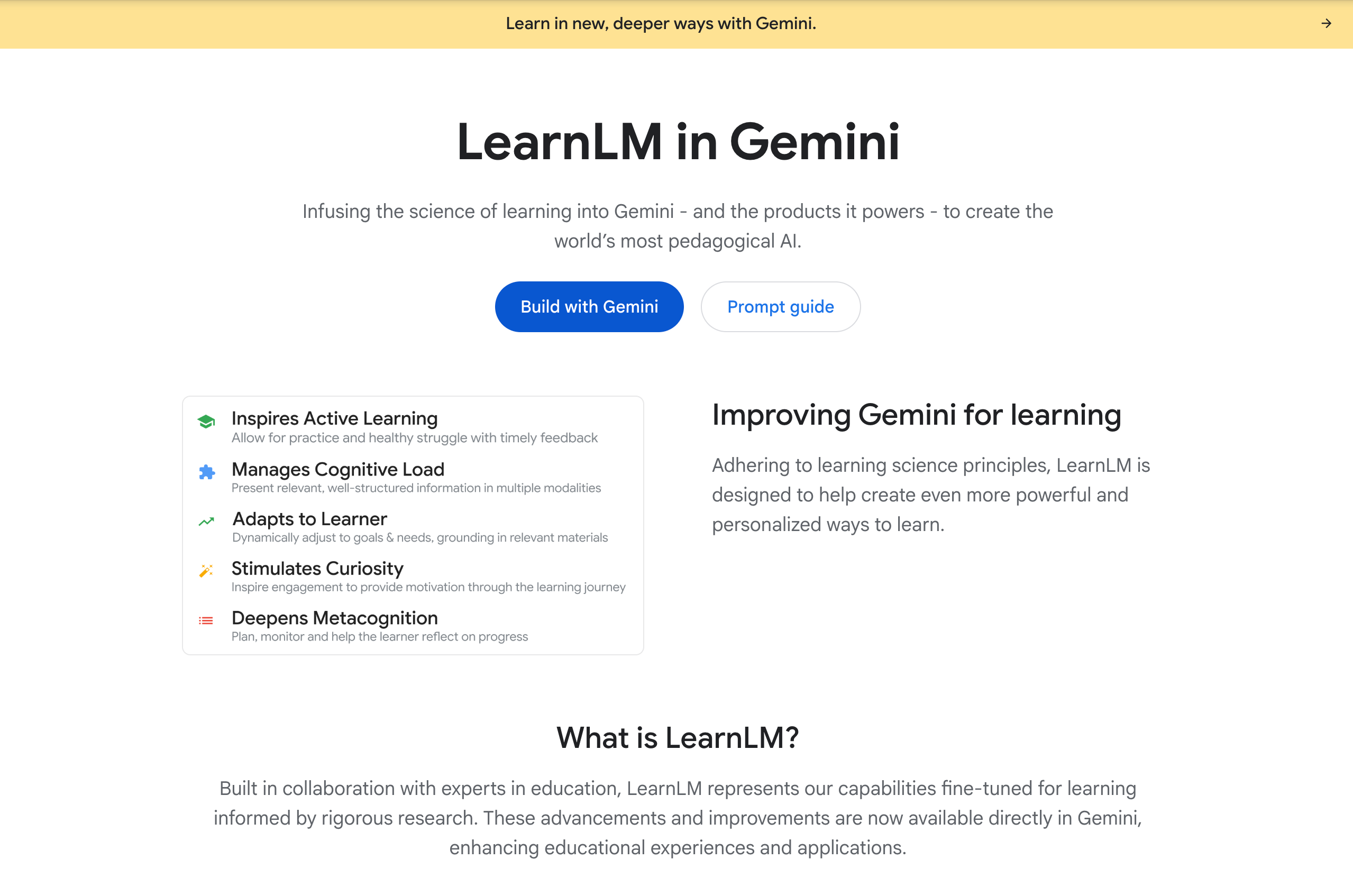
The Rise of Specialised LLMs, e.g. LearnLM
In response to some of the shortcomings of general LLMs, there is an increasing amount of discussion about the rise of “specialised” LLMs — i.e. models which are trained on specific sorts of data and optimised for specific sorts of tasks.
For us, the most important example of this is probably Google’s LearnLM: an LLM built specifically to “fix” the pedagogical shortcomings of general LLMs and optimise AI’s performance in learning and education-related tasks (try it for yourself in Google’s AI Studio, here).
Google hasn’t publicly revealed LearnLM’s exact dataset, but we know from published research papers that its training included:
Real tutor–learner dialogues
Real essays, homework problems, diagrams + expert feedback
Expert pedagogy rubrics collected from education experts to train reward models and guide tuning.
Education-focused guidelines, developed with education partners (e.g., ASU, Khan Academy, Teachers College, etc.).

LearnLM: a model fine-tuned for pedagogical quality

LearnLM’s pedagogical expertise is fine tuned both via the data it’s been trained on and by the system prompt it’s been given (i.e. how it’s been told to behave in the back end, by the people who built it) is also optimised to follow pedagogical best practices.
For example, it has likely been instructed “don’t give the answer; use Socratic prompts; adjust difficulty” etc. This is also how specialised “learning” modes like OpenAI’s & Copilot’s Study & Learn features and Gemini’s Guided Learning mode work.

While fine-tuning LLMs on specialised materials and editing system prompts enhances the pedagogical performance of AI models, all specialised “learning” LLMs and features have been fine-tuned with pedagogical materials on top of generic models.
In practice, this means that models like LearnLM and other “study and learn” modes are still powered by generic LLMs at their core — their responses are still shaped primarily by generic training materials, and they still predict text based on statistical likelihood, not verified truth or instructional validity.
TLDR: When working with LLMs, the risks for the L&D workflow and its impact on substantive learning are real:
Hallucination — LLMs invent plausible-sounding facts that aren’t true
Drift — LLM outputs wander from your brief without clear constraints
Generic-ness — LLMs surface that which is most common, leading to homogenisation and standardisation of “mediocre”
Mixed pedagogical quality — LLMs do not produce outputs which are guaranteed to follow evidence-based practice
Mis-calibrated trust — LLMs invite us to read guesswork as dependable, factual knowledge
These aren’t edge cases or occasional glitches—they’re inherent to how AI / all LLMs function. Prediction machines can’t verify truth. Pattern-matching can’t guarantee validity. Statistical likelihood doesn’t equal quality.
So, where does this leave an L&D profession which is embedding these tools into its tech stack at an increasing rate?
The answer (at least in the short term) isn’t build better AI—it’s better L&D workflows. We need to establish clear methods for AI use which actively optimise for its benefits while managing its known risks. In practice, this means developing a new sort of AI-augmented L&D workflow which intentionally:
constrains what AI can predict
grounds outputs in verified evidence
forces L&D professionals to own & maintain quality control at every step.
So, what might this look like in practice? To help answer this question, I put together an example, and called it FRAME™️.
Introducing FRAME™
FRAME™ is a 5-step AI workflow designed for L&D teams. It’s purpose is to tap into AI’s strengths (speed, creativity, pattern recognition) while intentionally offsetting its known weaknesses (guessing, drift, generic-ness).
Each step of the FRAME™ workflow is designed to optimise for quality control while also accelerating the workflow.
The results so far: AI-generated outputs that are consistently reliable, explainable, reusable, and backed by research—not guesswork.
Here’s how it works in practice:
🪜 Step 1: F — Find the Evidence
What you’re doing: Building AI’s instruction manual based on research.
Before you ask AI to create anything, define what “good” looks like using evidence, not assumptions.
Use AI-powered research tools—Consensus, Perplexity Pro, Elicit, or STORM by Stanford—to gather peer-reviewed findings about your specific task. These tools are built for academic retrieval and synthesis, which means they reduce noise and maintain higher traceability than general LLMs.
Example prompt for a research tool:
“What does peer-reviewed research say about writing effective learning objectives? Provide 5 evidence-based rules, 3 common mistakes to avoid, and 2 excellent examples for workplace safety training.”
Save the results as RESEARCH_SUMMARY.txt. This document is the instruction manual you’ll give to AI in the next steps.

Tips for this step:
Ask the research tool to format findings as rules or step-by-step instructions
Request both positive examples (what good looks like) and negative examples (common errors)
Include a list of misconceptions or pitfalls specific to your task
Save as .txt or .md formats—AI reads these formats most reliably
🪜 Step 2: R — Role & Rules Definition
What you’re doing: Setting clear expectations for who does what and what success looks like.
Vague requests produce vague results. Specific instructions produce specific, usable outputs.
Define:
Roles — Who’s the expert (you) and who’s the assistant (AI)
The Task — What exactly you’re asking AI to create
Success Criteria — How you’ll judge whether the output meets standards
Constraints — Non-negotiable rules (brand style, accessibility, tone, length)
Output Format — Exactly how you want the result delivered
Example:
“You are a detail-obsessed instructional design assistant specializing in learning objectives. I am the lead designer and your professor.
I will provide: a learner persona, a course goal, and a research summary.
Your task: write 5 sequenced learning objectives using ONLY the provided documents.
Present results in a table with three columns:
Objective (the full learning objective, in sequence)
Learner Rationale (why this objective fits this specific learner)
Research Alignment (which research principle from the summary this follows)”

Tips for this step:
Give AI a personality that drives performance (”detail-obsessed,” “accessibility-focused”)
Position AI as an expert, but position yourself as more expert—this raises the stakes and drives output quality
Use constraining language like “you must,” “only,” and “do not”—this reduces drift
Require AI to explain its rationale—this forces more deliberate decision-making
🪜 Step 3: A — Assemble Inputs
What you’re doing: Giving AI everything it needs so it stops guessing.
Upload all relevant documents:
RESEARCH_SUMMARY.txt(from Step 1)Learner persona or profile
Course goals
Brand/house style guide
Accessibility standards (e.g., WCAG)
Templates or previous examples
After uploading, explicitly tell AI which documents to use:
“Use the research summary and learner persona to create the objectives. Never invent information which is not present in these documents.”
File format matters. Here’s the reliability ranking for how well AI reads different formats:
.txt / .md — Minimal noise, clear structure (best)
JSON / CSV — Great for structured data
DOCX — Fine if formatting is simple
Digital PDFs — Extraction can mix headers, footers, columns
PPTX — Text order can be unpredictable
Scanned PDFs / images — Worst; requires OCR, highly error-prone
Also: use descriptive filenames that match content (e.g., LEARNER_PERSONA_warehouse_staff.md) — this reduces drift.
🪜 Step 4: M — Model, Measure, Modify
What you’re doing: Generate, critique, refine. Turn good into great.
AI’s first draft is rarely its best. This is where quality assurance happens.
The process:
Generate — Ask AI to create 2-3 different versions
Evaluate — Ask AI to critique its own work: “Review your three versions. What are the specific weaknesses in each?”
Compare — Ask AI to select the best version and explain why: “Which version best meets the brief? Explain your reasoning.”
Push harder — Challenge AI to go further: “What would make this output 10× closer to perfect? What additional information would help?”
Cross-check — If possible, run the same prompt in a different AI model. Paste both results back and ask: “Here’s an alternative version. Compare the two. Which is stronger and why? Create a hybrid that takes the best elements of both.”
Final verification:
Does the output align with your research summary?
Does it meet all constraints (accessibility, tone, format)?
Is it appropriate for your specific learner?
Is all information accurate and verifiable?
Are outputs consistently reliable across both common and edge use cases?
Research shows AI outputs improve significantly with iterative refinement. This step is where acceptable becomes excellent—and where you catch potential errors before they reach stakeholders.
🪜 Step 5: E — Expand & Embed
What you’re doing: Turning one-off prompts into reusable systems.
Once you’ve perfected a workflow, you have a proven recipe. Now you can decide how to operationalise it. There are three options:
Create a Prompt Template when you want to use it regularly for personal reuse only
Build a Custom GPT or Bot when you want to share a task-specific workflow with a team for cross-team quality and efficiency gains
Create an Automated Agent when you want to trigger the workflow automatically in certain conditions
Why FRAME™ Works
Tests of the FRAME™ method that I’ve run with L&D teams shows that structured approaches to AI integration have the potential to significantly increase the quality, consistency and velocity of L&D workflows.
By applying structured methods which actively optimise for the strengths of LLMs while managing their known risks, L&D teams can produce outputs with AI which are significantly (and consistently) higher quality than a) unstructured AI use and b) human-only workflows.
Why does adding structure to AI workflows work so well? Fundamentally, there are four key reasons. Methodologies like FRAME™:
Narrow the model’s probability space — Specific context and constraints reduce randomness and increase precision
Inject external evidence — User-provided research summary ground outputs in verified knowledge rather than mixed-quality training data
Create audit trails — Every output traces back to specific research principles and design decisions, making your work explainable and defensible
Lean into model strengths while compensating for weaknesses — AI excels at following structured instructions. FRAME™ uses this while offsetting the risks of guesswork and drifts through evidence and constraints.
Structured approaches to AI integration like FRAME™ turn ad-hoc AI adoption and unstructured prompting into a repeatable, evidence-based process that mirrors how expert instructional designers actually work and produces outputs that are reliable, explainable, auditable and backed by research—not guesswork.
Concluding Thoughts
Whether or not we are ready and willing, AI is transforming L&D. Over half of L&D teams have already embedded tools like ChatGPT and Copilot into their workflows—and that number is growing every month.
The opportunity is real: faster development, better scalability, and the ability to do more with less. But so too are the risks.
My research shows one thing very clearly: without structured methods, most L&D teams mis-calibrate their trust of AI, over relying on its ability to product reliable results while also under-optimising its potential to bring real value to their work (and their learners).

My take is that the responsibility for optimising the impact of AI on our work and ultimately our learners lies with us, its users. FRAME™ is an example of a structured workflow that empowers L&D folks to capture AI’s strengths—speed, creativity, pattern recognition, iteration—while actively and strategically managing its documented weaknesses.
The most successful L&D teams won’t sit around waiting for the perfect AI model, or ignore the limitations of the models we already have. The most successful L&D teams will use their expertise of how L&D works to build AI-augmented workflows that make today’s imperfect models work—and work well.
Download the playbook here and try FRAME™️ for yourself.
Happy experimenting!
Phil 👋
PS: If you want hands-on practice working with AI and applying structured methods like FRAME™️ to your work, join me for the next run of my AI & Learning Design Bootcamp.